结合深度学习预测每个用户的社交影响。
论文地址:https://arxiv.org/abs/1807.05560
ABSTRACT
脸书、推特、微信和微博等社交信息网络活动成为日常生活的重要组成部分,我们可以接触朋友的行为,同样的被他们影响。因此,对每一个用户的社交影响的有效预测对于如在线推荐和广告等各种应用至关重要。
传统的社交影响预测方法通常设计各种手工规则来提取用户和网络的特征。但是,这种方式的有效性严重依赖于领域专家的知识。结果,很难将他们泛化到不同的领域。受到最近深度神经网络在各种计算应用中的成功的启发,我们设计了一个端到端框架DeepInf1,以学习用户的潜在特征表示来预测社会影响。 通常,DeepInf将用户的本地网络作为图形神经网络的输入,用于学习其潜在的社交表示。 我们设计了将网络结构和用户特定特征纳入卷积神经网络和注意力网络的策略。 代表不同类型的社交和信息网络的Open Academic Graph,Twitter,Weibo和Digg的大量实验表明,提出的端到端模型DeepInf明显优于传统的基于特征工程的方法,表明了社交应用的有效表示学习。
INTRODUCTION
社会影响力无处不在,不仅在我们的日常生活中,而且在虚拟的网络空间。 社会影响一词通常指的是一个人的情绪,观点或行为受到他人影响的现象。 随着在线和移动社交平台的全球渗透,人们目睹了社会影响力在各个领域的影响,如总统选举[7],广告[3,24]和创新采用[42]。 到目前为止,毫无疑问,社会影响已经成为推动我们社会决策的普遍而复杂的力量,明确需要方法论来描述,理解和量化社会影响的潜在机制和动态。
实际上,在文献中已经对社会影响预测做了大量工作[26,32,42,43]。 例如,Matsubara等人 [32]通过精心设计从经典的“易感染的”(SI)模型扩展的微分方程,研究社会影响的动态; 最近,Li等人[26] 提出了一种通过结合递归神经网络(RNN)和表示学习来推断级联大小的端到端预测器。 所有这些方法主要旨在预测社会影响的全局或聚合模式,例如时间范围内的级联大小。 然而,在诸如广告和推荐的许多在线应用中,有效地预测每个个体的社交影响,即用户级社交影响预测是至关重要的。
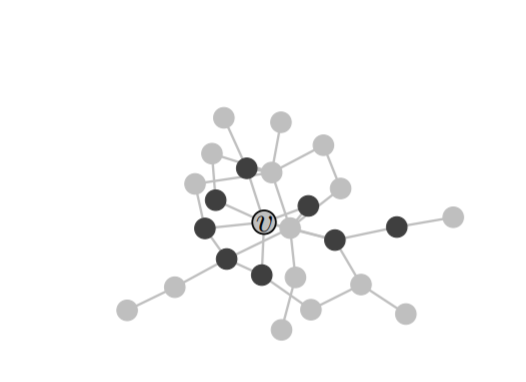
图1:社会影响局部性预测的一个激励性例子。目标是预测v的活动状态,给定 1)她近邻的观察活动状态(黑色和灰色的圆圈分别用来表示“活动”和“不活动”)和 2)他嵌入的本地网络。
在本文中,我们关注用户级社会影响力的预测。 我们的目标是在给定近邻居的行动状态和她的本地结构信息的情况下预测用户的行动状态。 例如,在图1中,对于中央用户v,如果她的一些朋友(black circles)购买了产品,她将来会购买相同的产品吗? 上述问题在现实世界的应用中很普遍,因为它经常被观察到其复杂性和非线性,例如[2]中的“S形”曲线和[46]中着名的“结构多样性”。 上述观察激发了许多用户级影响预测模型,其中大多数[27,53,54]考虑了复杂的手工制作的特征,这需要对特定领域的广泛了解,并且通常难以推广到不同的领域。
受到最近神经网络在表示学习中的成功启发,我们设计了一种端到端的方法来自动发现社会影响中的隐藏和预测信号。 通过将网络嵌入[37],图形卷积[25]和图形注意机制[49]构建到一个统一的框架中,我们期望端到端模型可以比使用特征工程的传统方法获得更好的性能。 具体而言,我们提出了一个基于深度学习的框架DeepInf,将影响动态和网络结构表示为潜在空间。 为了预测用户v的动作状态,我们首先通过随机漫步重新开始对她的本地邻居进行采样。 在获得如图1所示的本地网络之后,我们利用图形卷积和注意技术来学习潜在的预测信号。
我们展示了我们提出的框架在不同领域的四个社交和信息网络中的有效性和效率 - Open Academic Graph(OAG),Digg,Twitter和微博。 我们将DeepInf与几种传统方法进行比较,例如具有手工制作特征的线性模型[54]以及最先进的图分类模型[34]。 实验结果表明,DeepInf模型可以显着提高预测性能,展示了社交和信息网络挖掘任务的表示学习的前景。
本文的其余部分安排如下:第2节制定社会影响预测问题。 第3节详细介绍了拟议的框架。 在第4节和第5节,我们进行了广泛的实验和案例研究。 最后,第6节总结了相关工作,第7节总结了这项工作。
PROBLEM FORMULATION
定义2.1。 r-neighbors和r-ego network设G =(V,E)是一个静态社交网络,其中V表示用户集和E⊆V×V表示关系集。 对于用户v,其r-neighbors被定义为 $\Gamma_v^r = {u:d(u,v)≤r}$ 其中d(u,v)是最短路径距离(就跳数而言) 用户v的r-ego network是由 $\Gamma_v^r$ 引起的子网络,由 $G_v^r$ 表示。
定义2.2 社交活动社交网络中的用户执行社交活动,例如转推。 在每个时间戳t,我们观察到用户u的二元动作状态, $s_u^t∈{0,1}$ ,其中 $s_u^t=1$ 表示用户u在时间戳t之前或之后执行了此动作,并且 $s_u^t=0$ 表示用户尚未执行此操作。 这样的动作日志可以从许多社交网络获得,例如Twitter中的“转发”动作和学术社交网络中的引用动作。
鉴于上述定义,我们引入了社会影响局部性
,这相当于一种封闭的世界假设:用户的社会决策和行动仅受到网络内近邻的影响,而假设外部来源不存在。
问题1:社交影响局部性 v的行动状态的概率取决于她的r-ego网络 $G_v^r$ 和她的r-neighbors的行动状态。 更正式地,给定 $G_v^r$ 和 $s_v^t={s_u^t:u∈\Gamma_v^r {v}}$ ,社会影响局部性旨在量化在给定时间间隔Δt之后v的激活概率:
$$P(s_v^{t+∆t} | G_v^r,S_v^t)$$
实际上,假设我们有N个实例,每个实例是一个3元组(v,a,t),其中v是用户,a是社交动作,t是时间戳。 对于这样的3元组(v,a,t),我们也知道v的r-ego网络 $G_v^r$ ,v的r-neighbors- $S_v^t$ 的动作状态,以及v在t +Δt的未来动作状态 ,即 $s_v^{t+∆t}$。 然后我们将社会影响预测表示为二元图分类问题,可以通过最小化以下关于模型参数θ的负对数似然目标来解决:
$$\iota(θ)=-\sum_{i=1}^{N}log(P_θ (s_{v_i}^{t_i+∆t} | G_{v_i}^r,S_{v_i}^{t_i})) \tag{1}$$
特别是,在这项工作中,我们假设Δt足够大,也就是说,我们想要在观察窗口的末尾预测自我用户v的行动状态。
MODEL FRAMEWORK
在本节中,我们正式提出DeepInf,一种基于深度学习的模型,用于参数化方程1中的概率,并自动检测社会影响的机制和动态。 该框架首先对固定大小的子网络进行采样,作为每个r-ego网络的代理(参见第3.1节)。 然后将采样的子网络馈入具有小批量学习的深度神经网络(参见第3.2节)。 最后,将模型输出与基础事实进行比较,以最小化负对数似然损失。
Sampling Near Neighbors
给定用户v,提取她的r-ego网络 $G_v^r$ 的直接方式是从用户v开始执行广度优先搜索(BFS)。然而,对于不同的用户, $G_v^r$ 可以具有不同的大小。 同时,由于社交网络中的小世界属性, $G_v^r$ 的大小(关于顶点的数量)可能非常大[50]。 这种不同大小的数据不适合大多数深度学习模型。 为了解决这些问题,我们从v的r-ego网络中采样固定大小的子网,而不是直接处理r-ego网络。
采样方法的一个自然选择是执行随机重启(RWR)[45]。 受[2,46]的启发,这表明人们更容易受到活跃邻居的影响而不是非活动邻居,我们从自我用户v或其中一个活跃邻居随机开始随机游走。 接下来,随机游走以与每个边缘的权重成比例的概率迭代地行进到其邻域。 此外,在每个步骤中,为步行分配返回起始节点的概率,即,自我用户v或v的活动邻居之一。 RWR一直运行,直到它成功收集固定数量的顶点,用 $\overline{\Gamma_v^r}$ 表示,其中 $\overline{\Gamma_v^r}=n$ 。 然后我们将由 $\overline{\Gamma_v^r}$ 引起的子网 $\overline{G_v^r}$ 视为r-ego网络 $G_v^r$ 的代理,并且表示 $\overline{S_v^t} ={s_u^t:u∈\overline{\Gamma_v^r{v}}}$ 是v的采样邻居的动作状态。 因此,我们将方程1中的优化目标重新定义为:
$$\iota(θ)=-\sum_{i=1}^Nlog(P_θ (s_{v_i}^{t_i+∆t} | \overline{G_{v_i}^r},\overline{S_{v_i}^{t_i}})) \tag{2}$$
Neural Network Model
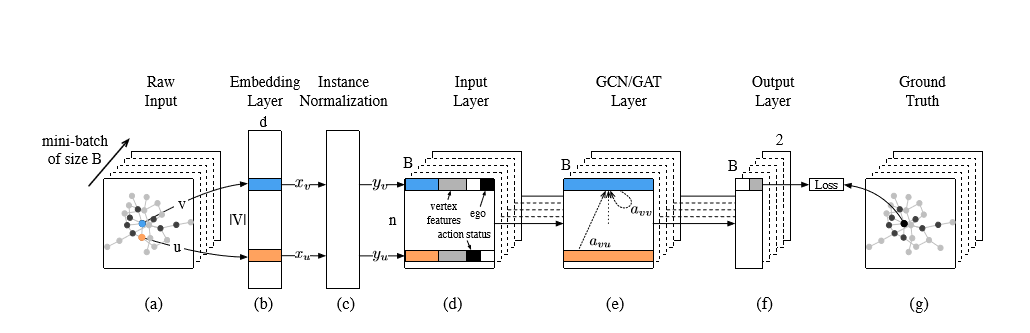
Figure 2: Model Framework of DeepInf.
利用每个用户检索到的 $\overline{\Gamma_v^r}$ 和 $\overline{S_v^t}$ ,我们设计了一个有效的神经网络模型,将 $\overline{\Gamma_v^r}$ 中的结构属性和 $\overline{S_v^t}$ 中的动作状态结合起来。 神经网络模型的输出是自我用户v的隐藏表示,然后用于预测她的动作状态- $s_v^{t+∆t}$ 。如图2所示,所提出的神经网络模型由网络嵌入层、实例归一化层、输入层、若干图形卷积或图形关注层以及输出层组成。 在本节中,我们逐一介绍这些层,并逐步构建模型。
嵌入层:随着最近出现的表示学习[5],网络嵌入技术得到了广泛的研究,以发现网络结构属性并将其编码为低维潜在空间。 更正式地,网络嵌入学习嵌入矩阵 $X∈R^{(D×|V|)}$ ,每列对应于网络G中的顶点(用户)的表示。在所提出的模型中,我们使用预训练 嵌入层将用户u映射到她的D维表示 $x_u∈R^D$ ,如图2(b)所示。
实例规范化:实例规范化是最近提出的图像样式转移技术[47]。 我们在社会影响力预测任务中采用这种技术。 如图2(c)所示,对于每个用户 $\overline{\Gamma_v^r}$ ,在从嵌入层检索她的表示 $x_u$ 之后,实例标准化 $y_u$ 由下式给出:
$$y_ud=\frac{(x_ud-μ_d)}{\sqrt{σ_d^2+ε}} \tag{3}$$
对于每个嵌入维度d = 1,···,D,其中
$$μ_d=\frac{1}{n}$$
$$\sum_{u∈\Gamma_v^r}{x_ud}$$
$$σ_d^2=\frac{1}{n}$$
$$\sum_{u∈\Gamma_v^r}{(x_{ud}-μ_d)^2} \tag{4} $$
(令人崩溃的markdown,怎么编辑公式都是不对,下面是截图。)
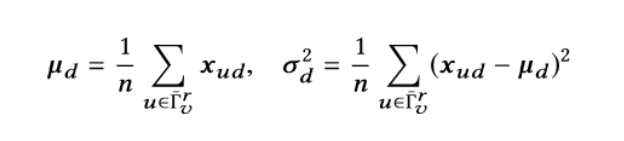
这里 $μ_d$ 和 $σ_d$ 是平均值和方差,ε是数值稳定性的小数。直观地,这种归一化可以去除特定于实例的均值和方差,这促使下游模型关注用户在潜在嵌入空间中的相对位置而不是其绝对位置。 正如我们稍后将在第5节中看到的那样,实例规范化可以帮助避免在训练期间过度拟合。
输入层:如图2(d)所示,输入层为每个用户构造一个特征向量。 除了归一化的低维嵌入来自上游实例规范化层之外,它还考虑了两个二进制变量。 第一个变量表示用户的动作状态,另一个表示用户是否是自我用户。 此外,输入图层还涵盖了所有其他自定义顶点要素,例如结构要素,内容要素和人口统计要素。
基于GCN的网络编码:图形卷积网络(GCN)是用于图形结构化数据的半监督学习算法。 通过堆叠多个GCN层来构建GCN模型。 每个GCN层的输入是顶点特征矩阵,$H∈R^{(n×F)}$,其中n是顶点的数量,F是特征的数量。 由 $h_i ^ T$ 表示的H的每一行与顶点相关联。 一般来说,GCN层的本质是非线性变换,输出 $H’∈R^{(n×F’)}$ 如下:
$$H’=GCN(H)=g(A(G)HW^T+b) \tag{5}$$
其中 $W∈R^{F’×F’}$ , $B∈R^{F’}$ 是模型参数,g是非线性激活函数,A(G)是捕获图G的结构信息的n×n矩阵。 GCN将A(G)实例化为与标准化图Laplaican [10]密切相关的静态矩阵:
$$A_{GCN}(G)=D^{-\frac{1}{2}} AD^{-\frac{1}{2}} \tag{6}$$
其中A是G的邻接矩阵,D = diag(A1)是度矩阵。
Multi-head Graph Attention :图注意(GAT)是最近提出的技术,它将注意机制引入GCN。 GAT通过自我关注机制定义矩阵 $A_{GAT}(G)=[a_{ij}]_{n×n}$ 。 更正式地,注意系数 $e_ij$ 首先由注意函数attn计算: $R^{F’}×R^{F’}→R$ ,其测量顶点j对顶点i的重要性:
$$e_{ij}=attn(W h_i ,W h_j)$$
与将计算所有实例对之间的注意系数的传统自注意机制不同,GAT仅评估 $e_ij$ 为 $(i,j)∈E(\overline{G_v ^ r})$ 或i = j,即(i, j)是边或自循环。 通过这样做,它能够更好地利用和捕获图形结构信息。 之后,为了使顶点之间的系数相当,采用softmax函数来归一化注意系数
$$a_{ij}=softmax(e_{ij})=\frac{exp(e_{ij})}{\sum_{k∈\Gamma_i^1} exp(e_{ik})}$$
继Velickovic等人之后。 [49],注意函数用点积和LeakyReLU [31,51]非线性实例化。 对于边或自循环(i,j),在参数c和两个端点- $W h_i$ 和 $W h_j$ 的特征向量的串联之间执行点积,即, $e_ij = LeakyReLU(c^T[ W h_i || W h_j])$,其中LeakyReLU的负斜率为0.2。 综上所述,归一化注意系数可表示为:
$$a_{ij}=\frac{exp(LeakyReLU( c^T [W h_i || W h_j] ))}{\sum_{k∈(\Gamma_i^1)}exp(LeakyReLU( c^T [W h_i || W h_k] ))} \tag{7}$$
|| 表示向量连接操作。
一旦获得归一化的注意系数,即aij,我们就可以将 $A_{GAT}(G)=[a_ij]_(n×n)$ 插入方程式。 这完成了单头(single-head)图注意的定义。 此外,我们应用Velickovic等人建议的多头(multi-head)图注意。 [49]和Vaswani等人。[48]。 多头(multi-head)注意机制并行地执行K个独立的单一注意,即,我们具有K个独立参数 $W_1,…,W_K$ 和注意矩阵 $A_1,…,A_K$ 。 多头注意力通过聚合函数将K单个注意力的输出聚合在一起:
$$H’=g(Aggregate(A_1 (G)HW_1^T,…,A_K(G)HW_K^T )+b) \tag{8}$$
我们连接每个单头注意的输出以聚合它们,除了最后一层的平均运算符。
输出层和损失函数:该层(见图2(f))为每个用户输出一个二维表示,我们将自我用户的表示与真值进行比较,然后如公式2所述优化对数似然损失。
小批量学习:当从r-ego网络采样时,我们强制采样的子网络具有固定大小n。 受益于这种同质性,我们可以在这里应用小批量学习进行有效的培训。 如图2(a)所示,在每次迭代中,我们首先将B实例随机抽样为小批量。 然后我们针对采样的小批量优化我们的模型。 这种方法比全批量学习运行得快得多,并且在优化期间仍然引入了足够的噪声。
EXPERIMENT SETUP
设置我们使用大规模实际数据集建立实验,以定量评估提出的DeepInf框架。
Datasets
| OAG | Digg | |||
|---|---|---|---|---|
| |V| | 953,675 | 279,630 | 456,626 | 1,776,950 |
| |E| | 4,151,463 | 1,548,126 | 12,508,413 | 308,489,739 |
| N | 499,848 | 24,428 | 499,160 | 779,164 |
Table1:Summary of datasets.|V|and|E|indicates the number of vertices and edges in graphG = (V,E), while N is the number of social influence locality instances(observations) as described in Section 2.
OAG: OAG(开放学术图)数据集是通过链接两个大型学术图表生成的:Microsoft Academic Graph [15]和AMiner [44]。 与[13]中的处理类似,我们从数据挖掘,信息检索,机器学习,自然语言处理,计算机视觉和数据库研究社区中选择了20个热门会议。 社交网络被定义为共同作者网络,社会行为被定义为引用行为 - 研究人员引用了上述会议的论文。 我们对她的合作者如何影响一个人的引用行为感兴趣。
Digg: Digg是一个新闻聚合器,允许人们对网页内容也就是故事进行投票,向上或向下投票。 该数据集包含有关2009年一个月内推广到Digg首页的故事的数据。对于每个故事,它包含所有Digg用户的列表,这些用户在数据收集和每次投票的时间戳之前已经投票选出了故事。投票者的友谊链接也被检索。
Twitter: Twitter数据集是在2012年7月4日宣布发现具有难以捉摸的希格斯玻色子特征的新粒子之前,期间和之后监测Twitter上的传播过程之后建立的。社交网络被定义 成为Twitter友谊网络,社交行为被定义为用户是否转发“希格斯”相关推文。
微博:微博是中国最受欢迎的微博服务。 数据集来自[53]并可在此处下载 (https://www.aminer.cn/influencelocality). 完整数据集包含2012年9月28日至2012年10月29日期间1,776,950位用户的定向跟踪网络和推文(发布日志)。社交行为定义为 微博中的转发行为 - 用户转发(转发)帖子(推文)。
数据准备:我们按照现有工作中的实践处理上述四个数据集[53,54]。更具体地,对于在某个时间戳t受到影响以执行社交动作a的用户v,我们生成肯定的实例。接下来,对于受影响的用户v的每个邻居,如果在我们的观察窗口中从未观察到她是活动的,我们创建一个否定实例。我们的目标是区分积极情况和消极情况。然而,所实现的数据集在两个方面面临数据不平衡问题。第一个来自活跃邻居的数量。正如Zhang等人所观察到的那样,当自我用户具有相对大量的活动邻居时,结构特征与社会影响局部性显着相关。然而,在大多数社会影响数据集中,活动邻居的数量是不平衡的。例如,在微博中,大约80%的实例只有一个活动邻居,活动邻居数量≥3的实例仅占8.57%。因此,当我们在这样的不平衡数据集上训练我们的模型时,模型将由几个活动邻居的观察主导。为了解决不平衡问题并显示我们的模型在捕获局部结构信息方面的优越性,我们过滤掉了几个活跃邻居的观察结果。特别是,在每个数据集中,我们仅考虑自我用户具有≥3个活动邻居的情况。第二个问题来自标签不平衡。例如,在微博数据集中,负实例与正实例之间的比率约为300:1。为了解决这个问题,我们采样了一个更平衡的数据集,其中负数和正数之比为3:1。
Evaluation Metrics
为了定量评估我们的框架,我们使用以下性能指标:
预测性能:我们根据曲线下面积(AUC)[8],精确度(精确度),召回量(Rec。)和F1度量值(F1)来评估DeepInf的预测性能。
参数灵敏度:我们在模型中分析了几个超参数,并测试了不同的超参数选择如何影响预测性能。
案例研究:我们使用案例研究来进一步证明和解释我们提出的框架的有效性。
| Name | Description |
|---|---|
| Vertex | Coreness[4]. Pagerank[35]. Hub score and authority score[9]. Eigenvector Centrality[6]. ClusteringCoefficient[50]. Rarity(reciprocalofegouser’sdegree)[1]. |
| Embedding | Pre-trainednetworkembedding(DeepWalk[36],64-dim). |
| Ego | Thenumber/ratio of active neighbors[2]. Density of subgnetwork induced by active neighbors[46]. #Connected components formed by active neighbors[46]. |
Table2:List of features used in this work.
Comparison Methods
我们将DeepInf与几个基线进行比较。
Logistic回归(LR):我们使用逻辑回归(LR)来训练分类模型。 该模型考虑了三类特征:(1)自我用户的顶点特征; (2)针对自我用户的预训练网络嵌入(DeepWalk [36]); (3)手工制作的网络功能。 我们使用的功能列于表2中。
支持向量机(SVM):我们还使用支持向量机(SVM)(线性核)作为分类模型。 该模型使用与逻辑回归(LR)相同的特征。
PSCN:当我们将社会影响局部性预测模型化为图分类问题时,我们将我们的框架与最先进的图分类模型PSCN [34]进行比较。对于每个图,PSCN根据用户定义的排名函数(例如,度和中介中心性)选择w个顶点。 然后,对于每个选定的顶点,它根据广度优先搜索顺序组装其邻近的顶部k。 对于每个图,上述过程构造具有F通道的长度为w×k的顶点序列,其中F是每个顶点的特征数。 最后,PSCN在其上应用1维卷积层。
DeepInf及其变体:我们实现了DeepInf的两个变体,分别由DeepInf-GCN和DeepInf-GAT表示。 DeepInfGCN使用图卷积层作为我们框架的构建块,即在公式5中设置 $A(G)=D^{-\frac{1}{2}} AD^{-\frac{1}{2}}$ 。 DeepInf-GAT使用图表注意,如公式7所示。但是,DeepInf和PSCN都只接受顶点级特征。 由于此限制,我们不在这两个模型中使用自我网络功能。 相反,我们希望DeepInf能够自动发现自我网络特征和其他预测信号。
超参数设置和实现细节:对于我们的框架DeepInf,我们首先以重启概率0.8执行随机游走,并且采样子网的大小设置为50.对于嵌入层,64维网络嵌入使用DeepWalk进行预训练[36]。然后我们选择为DeepInf使用三层GCN或GAT结构,第一和第二GCN / GAT层都包含128个隐藏单元,而第三层(输出层)包含2个用于二进制预测的隐藏单元。特别是对于具有多头图关注度的DeepInf,第一层和第二层都由K = 8个注意头组成,每个计算16个隐藏单元(总共8×16 = 128个隐藏单元)。对于详细的模型配置,我们采用指数线性单位(ELU)[11]作为非线性(方程5中的函数д)。所有参数都用Glorot初始化[18]初始化,并使用Adagrad [16]优化器进行训练,学习率为0.1(Digg数据集为0.05),权重衰减为 $5e^{-4}$(Digg数据集为 $1e^{-3}$),辍学率为0.2。我们分别使用75%,12.5%,12.5%的实例进行培训,验证和测试;所有数据集中的小批量大小都设置为1024。
至于PSCN,在我们的实验中,我们发现推荐的中介中心性排名函数在预测社会影响方面效果不佳。我们转而使用从自我用户开始的广度优先搜索顺序作为排名函数。当BFS订单不是唯一的时,我们首先通过对活跃用户进行排名来打破关系。我们通过验证选择w = 16和k = 5,然后应用两个1维卷积层。第一个转换层有16个输出通道,步幅为5,内核大小为5.第二个转换层有8个输出通道,步长为1,内核大小为1.第二层的输出则为进入完全连接的层以预测标签。
最后,我们允许PSCN和DeepInf在训练数据上运行最多500个时期,并且通过在验证集上使用损失提前停止来选择最佳模型。 我们在https://github.com/xptree/DeepInf上发布了PSCN和DeepInf的代码,这两个代码都是用PyTorch实现的。
结论
在这项工作中,我们研究社会影响局部性问题。 我们从深度学习的角度阐述了这个问题,并通过结合最近开发的网络嵌入,图形卷积和自我关注技术,提出了基于图形的学习框架DeepInf。 我们在四个社交和信息网络-OAG,Digg,Twitter和微博上测试提议的框架。 我们广泛的实验分析表明,DeepInf在预测社会影响局部性方面明显优于具有丰富手工工艺特征的基线。 这项工作探讨了网络表征学习在社会影响力分析中的潜力,并首次尝试解释社会影响力的动态。
提出的DeepInf背后的一般思想可以扩展到许多网络挖掘任务。 我们的DeepInf可以有效地汇总网络中的本地区域。 然后,可以将这样的概括表示馈送到各种下游应用中,例如链路预测,相似性搜索,网络对齐等。因此,我们希望探索这个有希望的方向以用于将来的工作。 另一个激动人心的方向是近邻的采样。 在这项工作中,我们在没有考虑任何辅助信息的情况下执行随机重启。 同时,采样程序与神经网络模型松散耦合。 通过利用强化学习将抽样和学习结合起来也是令人兴奋的。